from pathlib import Path
import numpy as np
import scipy.io
import matplotlib.pyplot as plt
from scipy.signal import butter, filtfilt, iirnotch
from sklearn.cross_decomposition import CCA
DATA_DIR = Path("data")
STIM_FREQS = [9, 10, 12, 15]
N_HARMONICS = 2
SUB_BANDS = [(6, 14), (14, 22), (22, 30), (30, 40)]
mat = scipy.io.loadmat(DATA_DIR / "subject_2_fvep_led_training_2.mat")
fs = int(mat["fs"][0, 0])
y = mat["y"]
def make_filters(fs, low=5.0, high=40.0, line=50.0, order=4, notch_q=30):
bp_b, bp_a = butter(order, [low, high], btype="band", fs=fs)
n_b, n_a = iirnotch(line, notch_q, fs=fs)
return (bp_b, bp_a), (n_b, n_a)
def apply_filters(x, bp, notch):
return filtfilt(*notch, filtfilt(*bp, x))
def find_trials(y):
ch10 = y[9].astype(int)
active = (ch10 != 0).astype(int)
diff = np.diff(active)
starts = np.where(diff == 1)[0] + 1
ends = np.where(diff == -1)[0] + 1
return [(int(s), int(e), int(ch10[s])) for s, e in zip(starts, ends)]
def build_template(freq, n_samples, fs, n_harmonics=N_HARMONICS):
t = np.arange(n_samples) / fs
refs = []
for h in range(1, n_harmonics + 1):
refs.append(np.sin(2 * np.pi * h * freq * t))
refs.append(np.cos(2 * np.pi * h * freq * t))
return np.stack(refs, axis=1)
def cca_score(X, Y):
cca = CCA(n_components=1, max_iter=500)
cca.fit(X, Y)
Xc, Yc = cca.transform(X, Y)
return float(np.corrcoef(Xc.ravel(), Yc.ravel())[0, 1])
def cca_predict(epoch, fs):
n = epoch.shape[1]
scores = [cca_score(epoch.T, build_template(f, n, fs)) for f in STIM_FREQS]
return STIM_FREQS[int(np.argmax(scores))]
def fbcca_predict(epoch, fs, sub_bands=SUB_BANDS, a=1.25, b=0.25):
n = epoch.shape[1]
weights = np.array([(i + 1) ** -a + b for i in range(len(sub_bands))])
band_signals = []
for low, high in sub_bands:
b_, a_ = butter(4, [low, high], btype="band", fs=fs)
band_signals.append(filtfilt(b_, a_, epoch, axis=-1))
scores = np.zeros(len(STIM_FREQS))
for fi, freq in enumerate(STIM_FREQS):
Y = build_template(freq, n, fs)
for bi, sig in enumerate(band_signals):
scores[fi] += weights[bi] * cca_score(sig.T, Y) ** 2
return STIM_FREQS[int(np.argmax(scores))]
bp, notch = make_filters(fs)
y_filt = y.astype(float).copy()
for ci in range(1, 9):
y_filt[ci] = apply_filters(y[ci], bp, notch)
trials = find_trials(y)
n_samples_full = trials[0][1] - trials[0][0]
epochs = np.stack([y_filt[1:9, s:s + n_samples_full] for s, _, _ in trials])
labels = np.array([fr for _, _, fr in trials])
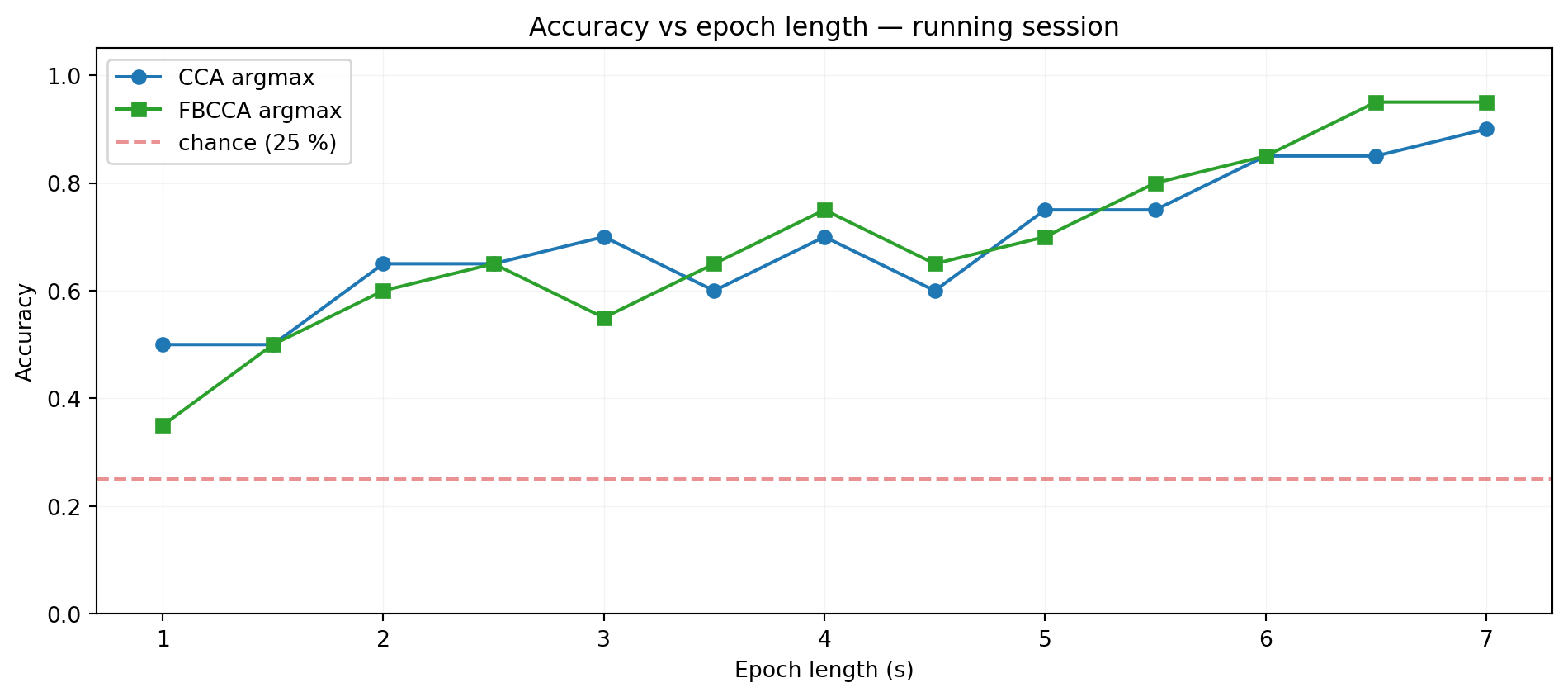
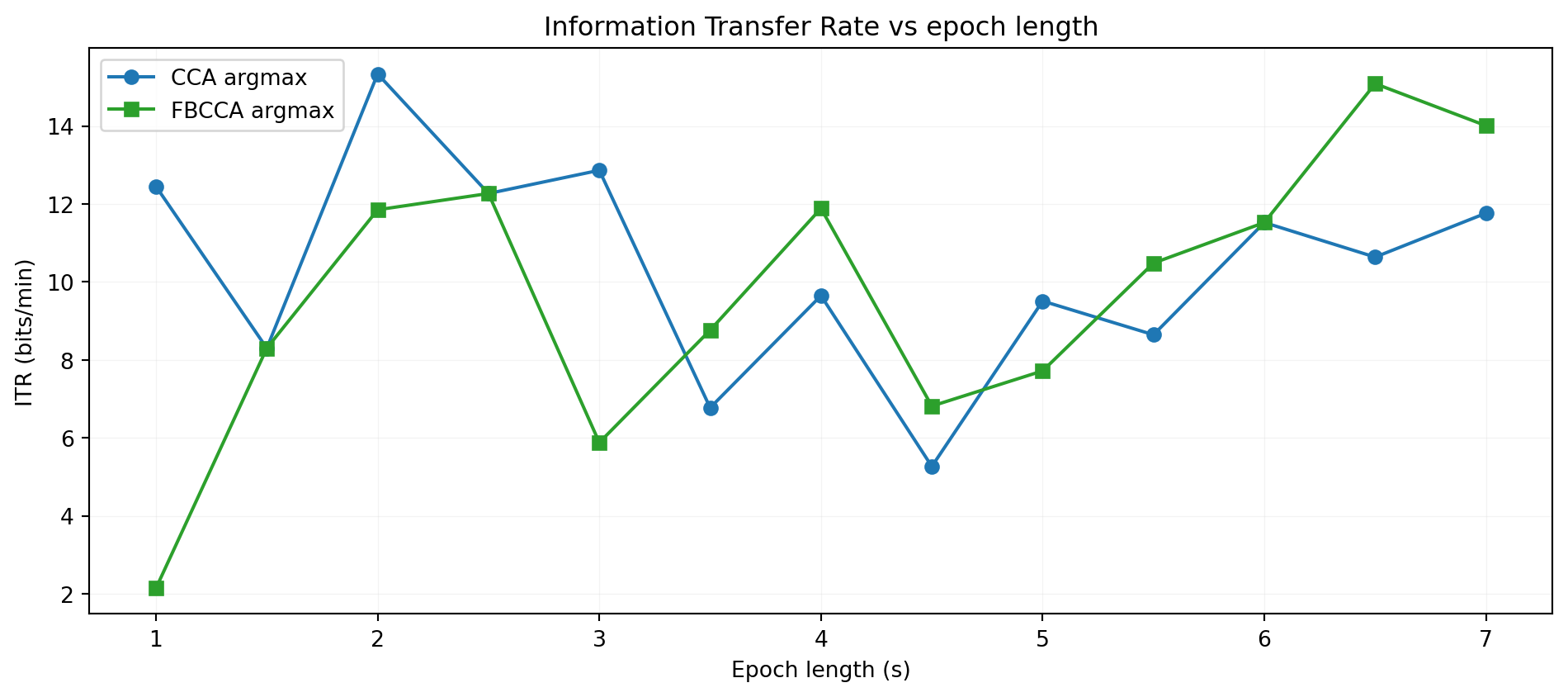
print(f"epochs: {epochs.shape}, full trial = {n_samples_full / fs:.2f} s")