Turn each epoch into a feature vector a classifier can use. The most direct route for SSVEP: compute a PSD per epoch, sample the amplitude at each candidate stimulation frequency and its harmonics, and stack those into a feature row.
5.1 Setup: load, filter, epoch
The pipeline from Ch 3 + Ch 4 in compact form: load the running session, bandpass + notch the eight EEG channels, build the (n_trials, 8, n_samples) epoch tensor.
For each of the eight EEG channels we compute Welch’s PSD on the epoch, then read off the amplitude at each candidate stimulation frequency (9, 10, 12, 15 Hz) and its second harmonic (18, 20, 24, 30 Hz). That’s eight values per channel × eight channels = 64 features per trial.
Code
NPERSEG =512# 0.5 Hz resolution at fs = 256 Hzdef channel_psd(channel, fs, nperseg=NPERSEG):return welch(channel, fs=fs, nperseg=min(nperseg, len(channel)))def epoch_features(epoch, fs):"""Return a (n_channels * len(STIM_FREQS) * len(HARMONICS),) feature vector.""" feats = []for ch inrange(epoch.shape[0]): ff, pxx = channel_psd(epoch[ch], fs)for f in STIM_FREQS:for h in HARMONICS: feats.append(pxx[np.argmin(np.abs(ff - h * f))])return np.array(feats)print(f"Feature vector for epochs[0]: shape = {epoch_features(epochs[0], fs).shape}")
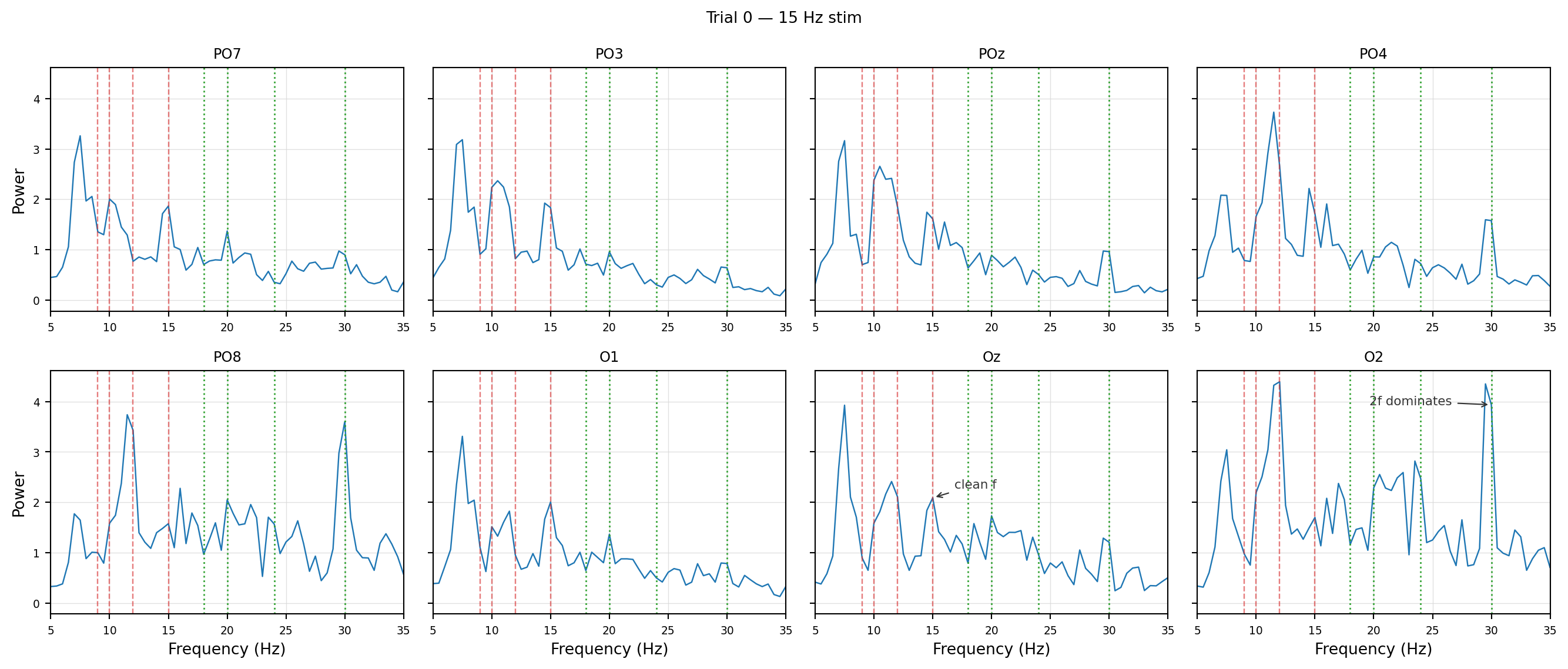
Figure 5.1: Per-channel PSD for one epoch (15 Hz class). Red dashed lines mark the four fundamentals; green dotted lines mark the four second harmonics. The classifier sees the PSD value at each of these eight frequencies on each of the eight channels.
For this 15 Hz trial the cleanest peaks at 15 Hz are on Oz, O1, PO7 and PO3 — occipital and left-lateralized. The right-side channels (O2, PO8) have a fat neighbourhood around 15 Hz that almost swallows the peak. Strikingly, the 30 Hz harmonic flips the picture: it’s small on the left channels but dominant on the right (on O2 and PO8 the 30 Hz peak is more than twice the 15 Hz fundamental). So the fundamental and the harmonic carry different spatial information on the same trial — another reason to keep all eight channels and both harmonics in the feature vector rather than betting everything on Oz at f.
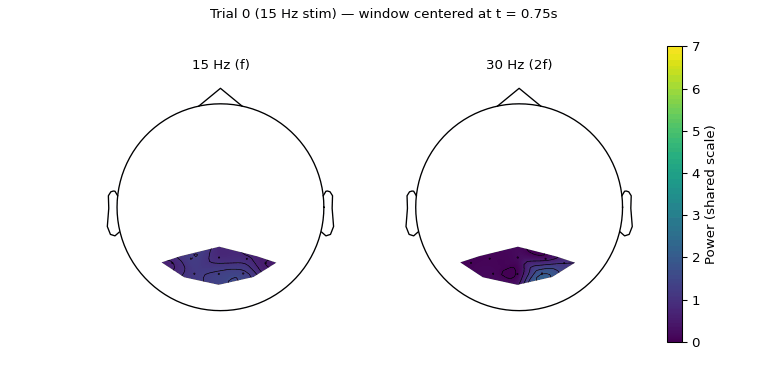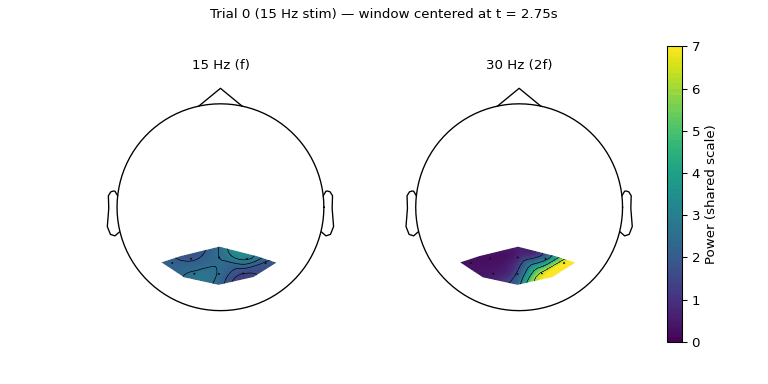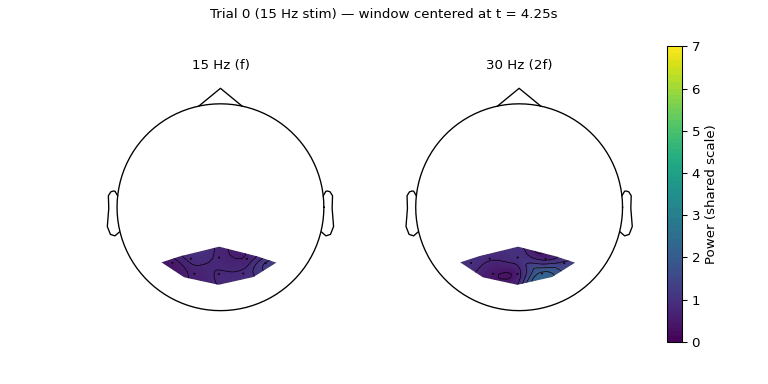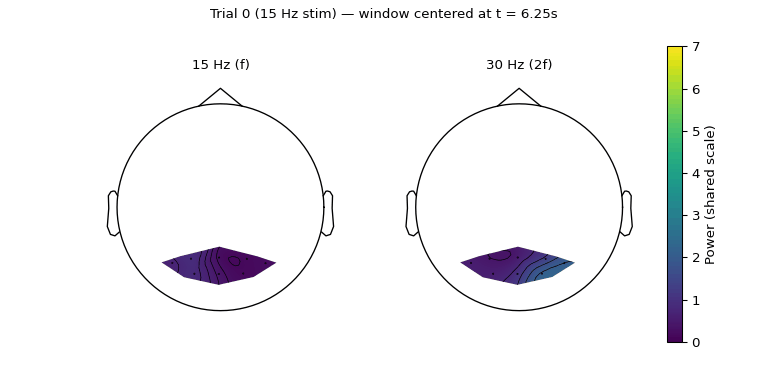
The same eight numbers, viewed on the scalp, make this even more vivid:
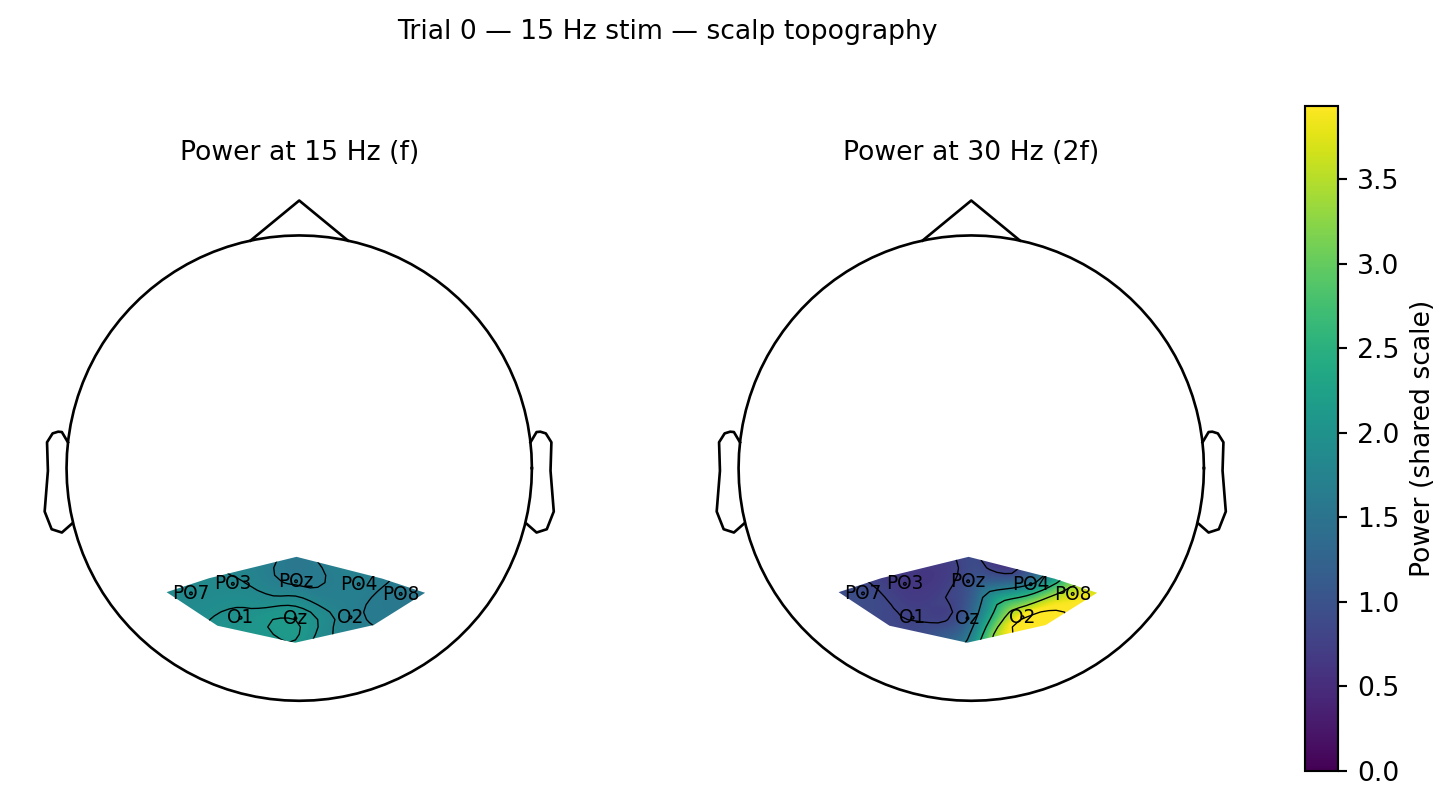
Figure 5.2: Scalp topography of band power for the same epoch, restricted to the convex hull of the eight electrodes and on a shared colour scale so the two bands are directly comparable. Left: the 15 Hz fundamental sits broadly across occipital cortex with a left bias. Right: the 30 Hz harmonic is sharply lateralized to the right (O2/PO8) and outside that hot spot is weaker than the fundamental.
A static topography averages over the whole 7.5 s epoch and hides any time evolution. Sliding a short window through the trial and re-rendering both topomaps frame-by-frame shows where and when the response actually builds up.
Figure 5.3: Sliding 1.5 s window (0.5 s hop) through the 7.5 s trial. Both panels share a colour scale derived from the per-window maximum across both bands, so brightness is directly comparable across frames and bands. The 15 Hz response appears almost immediately and stays broadly distributed; the 30 Hz response builds up later and concentrates on the right occipital electrodes.
Sampling at expected frequencies — rather than feeding the entire 5–40 Hz spectrum to the classifier — collapses each PSD to a small, physically meaningful number of values: it bakes in what we know about the experiment, gives the model fewer features to overfit to, and is robust to per-trial scaling differences.
5.3 The feature matrix for a whole session
Code
feat_matrix = np.stack([epoch_features(epochs[i], fs) for i inrange(len(epochs))])print(f"feat_matrix shape: {feat_matrix.shape} (n_trials, n_channels × n_stimulation_frequencies × n_harmonics)")
order = np.lexsort((np.arange(len(labels)), labels))sorted_feat = feat_matrix[order]sorted_labels = labels[order]n_per_block =8# 8 channels sampled at each (stimulation frequency, harmonic)group_labels = [f"{h * f} Hz"for f in STIM_FREQS for h in HARMONICS]fig, ax = plt.subplots(figsize=(13, 5))im = ax.imshow(sorted_feat, aspect="auto", origin="upper", cmap="viridis", norm=LogNorm())for i inrange(1, len(group_labels)): ax.axvline(i * n_per_block -0.5, color="white", lw=0.8)class_changes = np.where(np.diff(sorted_labels) !=0)[0] +0.5for r in class_changes: ax.axhline(r, color="white", lw=0.8)ax.set_xticks([i * n_per_block + n_per_block /2-0.5for i inrange(len(group_labels))])ax.set_xticklabels(group_labels)ax.set_xlabel("Feature group (eight channels sampled at each frequency)")yt = [np.where(sorted_labels == c)[0].mean() for c insorted(set(sorted_labels))]ax.set_yticks(yt)ax.set_yticklabels([f"{c} Hz"for c insorted(set(sorted_labels))])ax.set_ylabel("Trial class (5 trials each)")fig.colorbar(im, ax=ax, label="Power (log scale)")fig.tight_layout()fig.savefig("images/05-spectral-features_matrix.png", dpi=200, bbox_inches="tight")plt.show()
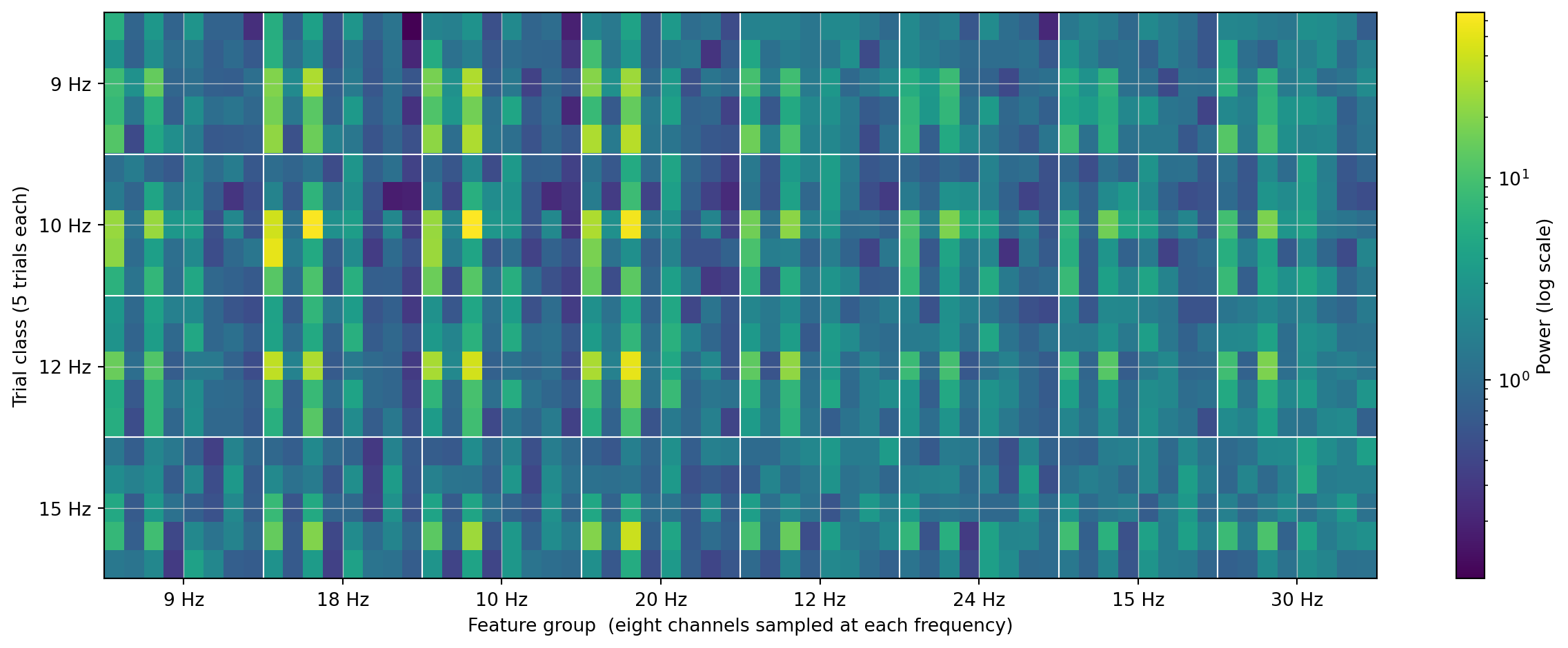
Figure 5.4: Feature matrix, rows sorted by stimulation class. Each row is one trial; each column is one (channel, frequency, harmonic) feature. Vertical lines separate frequency-and-harmonic groups.
How to read this heatmap: each row is one trial, each column is one of the 64 features (8 channels × 8 sampled frequencies). Rows are sorted so the five 9 Hz trials sit at the top, then the 10, 12, and 15 Hz blocks below. Columns are grouped by sampled frequency — the leftmost eight columns are all “PSD power at 9 Hz, one per channel”; the next eight are “PSD power at 18 Hz” (the second harmonic of 9 Hz); and so on through 30 Hz.
Class structure shows up as bright cells lining up along the column whose frequency matches the row’s class. The top five rows (9 Hz) are brightest in the 9 Hz column block — exactly where you’d expect — and you can also see them light up in the 18 Hz column block, which is the second harmonic. That’s the harmonics earning their place in the feature vector: they fire independently of the fundamental, adding evidence rather than duplicating it. The 10 Hz row block follows the same pattern at 10 and 20 Hz. Where the eye can already separate the classes from the matrix alone, a linear classifier almost certainly can too.
The 12 and 15 Hz row blocks look noticeably dimmer than 9 and 10 Hz — same story as Ch 2: those classes have weaker raw-power features on this subject (12 Hz overlaps with alpha, 15 Hz drives a smaller harmonic). The classifier has less to work with there.
5.4 A strawman classifier
Before reaching for fancier features, ask the simplest possible question: how far does raw power on its own get you? For each trial, sum the feature row over channels and harmonics per stimulation frequency, then pick the frequency with the most total power. No training, no normalization, no model — pure argmax over the matrix above.
Code
power_per_freq = feat_matrix.reshape(len(epochs), len(EEG_LABELS), len(STIM_FREQS), len(HARMONICS)).sum(axis=(1, 3))naive_pred = np.array([STIM_FREQS[i] for i in power_per_freq.argmax(axis=1)])naive_acc = (naive_pred == labels).mean()print(f"Raw-power argmax: {(naive_pred == labels).sum()}/{len(labels)} = {naive_acc:.0%}")
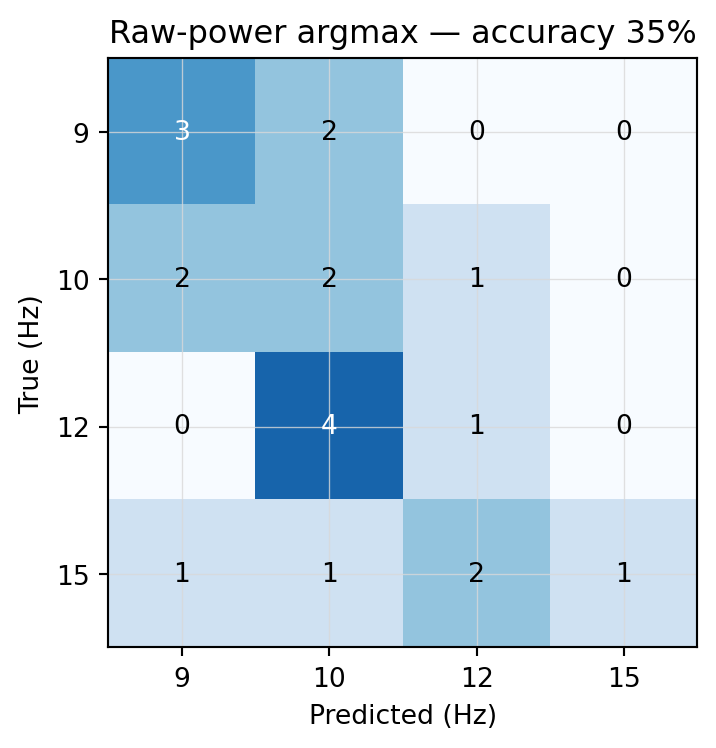
Raw-power argmax: 7/20 = 35%
Code
cm = np.zeros((len(STIM_FREQS), len(STIM_FREQS)), dtype=int)for t, p inzip(labels, naive_pred): cm[STIM_FREQS.index(int(t)), STIM_FREQS.index(int(p))] +=1cm_norm = cm / np.maximum(cm.sum(axis=1, keepdims=True), 1)fig, ax = plt.subplots(figsize=(5, 4))ax.imshow(cm_norm, cmap="Blues", vmin=0, vmax=1)for i inrange(len(STIM_FREQS)):for j inrange(len(STIM_FREQS)): ax.text(j, i, f"{cm[i, j]}", ha="center", va="center", fontsize=10, color="white"if cm_norm[i, j] >0.5else"black")ax.set_xticks(range(len(STIM_FREQS)))ax.set_xticklabels([str(f) for f in STIM_FREQS])ax.set_yticks(range(len(STIM_FREQS)))ax.set_yticklabels([str(f) for f in STIM_FREQS])ax.set_xlabel("Predicted (Hz)")ax.set_ylabel("True (Hz)")ax.set_title(f"Raw-power argmax — accuracy {naive_acc:.0%}")fig.tight_layout()fig.savefig("images/05-spectral-features_naive_confusion.png", dpi=200, bbox_inches="tight")plt.show()
Figure 5.5: Raw-power argmax — confusion matrix. Cells show trial counts; shading is row-normalized.
The diagonal is uneven. Classes whose fundamental sits inside the alpha band bleed into each other in the predictable way: raw power can’t tell a true 10 Hz SSVEP peak apart from spontaneous 10 Hz alpha — both are just a bin with high power. Something needs to weigh peaks against their local background, not just measure their absolute height.
5.5 SNR features
Raw amplitude features are sensitive to the per-trial overall level — attention, electrode drift across the session, residual 1/f tilt. We can normalize each sampled bin by the average amplitude in its neighbourhood, turning power into a signal-to-noise ratio. The peak still has to stand out against its background, not merely be tall in absolute terms.
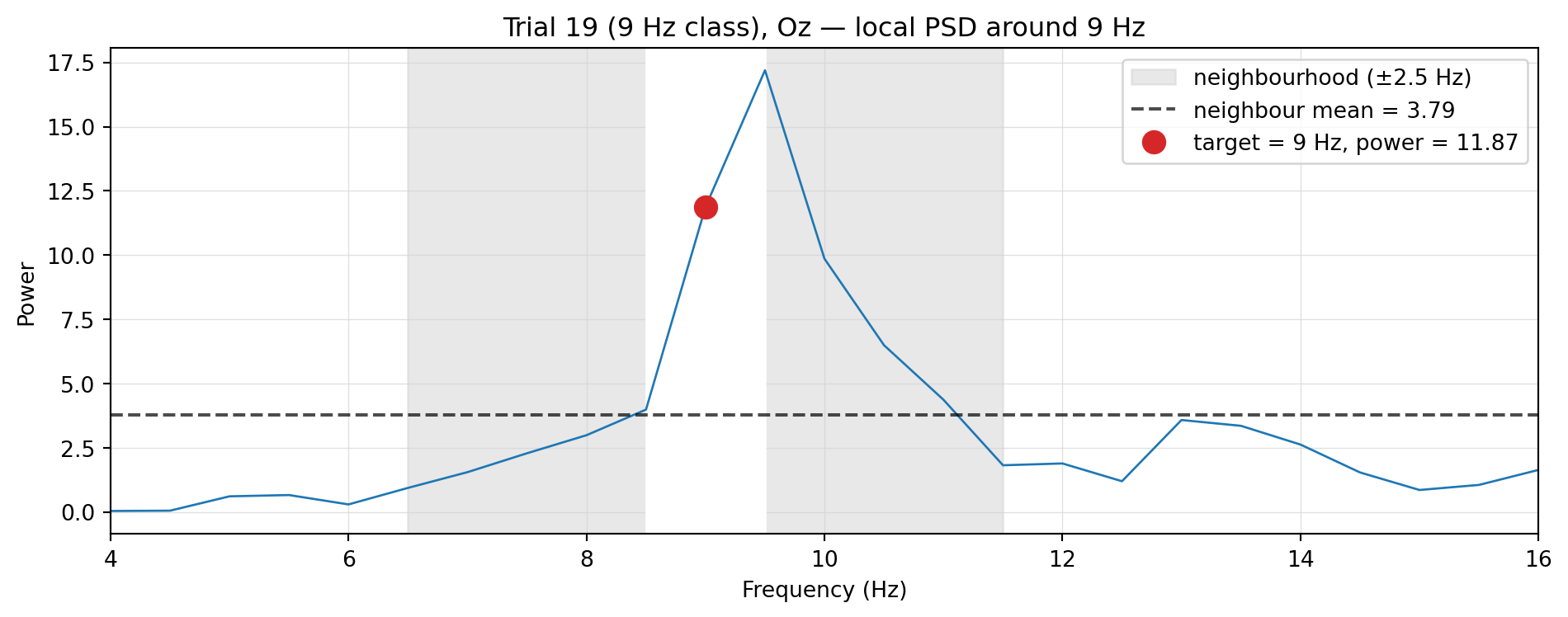
To make the transformation concrete, take a single cell from the matrix above: the 9 Hz feature on Oz for the last 9 Hz trial (one of the cleanest single-trial SSVEPs in the session). Here’s its local PSD around 9 Hz:
Figure 5.6: Local PSD on Oz for the last 9 Hz trial. The target bin (red) sits well above the average of its flanking neighbours (dashed line) — the SNR feature is the ratio of the two.
The target sits about 3× above its background — that’s the SNR feature value for this single cell. The same calculation runs across all 64 (channel × frequency) entries of the matrix.
Note
Why ±2.5 Hz for the neighbourhood? A balance between two pressures. Wide enough to span the alpha bump (itself ~2–3 Hz wide) so alpha doesn’t get counted as “signal” sitting right next to its target, and to leave enough bins for a stable noise mean. Narrow enough that EEG’s 1/f tilt doesn’t average across very different noise regimes (the floor at 9 Hz is genuinely higher than at 30 Hz), and to keep the band clear of neighbouring harmonic families — for f = 15 Hz, the 12.5–17.5 Hz neighbourhood stops short of 18 Hz, which is the 2f harmonic of the 9 Hz class. The ±0.6 Hz exclusion carves out the target peak itself plus its Welch-leakage skirts. Adjacent stim classes are as close as 1 Hz apart, so other stim frequencies do fall inside the band — that’s fine because only one class is driven per trial, so there’s no rival peak to pollute the estimate.
What does the transformation actually do? Take a contrasting cell from the same trial: the 12 Hz feature on Oz has raw power 1.89 (small) but its neighbourhood includes the alpha bump near 10 Hz, so the neighbour mean is 6.13. Their ratio is 0.31 — well below 1, signalling “this bin sits below its surroundings”, i.e. there is no SSVEP peak at 12 Hz on this trial. Raw power can’t make that distinction; SNR can. The cell’s pre/post values: raw = 1.89, SNR = 0.31. Both numbers go into the heatmap as “low”, but the SNR version is more committed about it.
Code
def snr_at(ff, pxx, f_target, half_bw_hz=0.6, neigh_hw_hz=2.5):"""Power at the target bin / mean power in a flanking neighborhood, excluding ±half_bw_hz around the target.""" df = ff[1] - ff[0] excl =max(1, int(round(half_bw_hz / df))) half =int(round(neigh_hw_hz / df)) target = np.argmin(np.abs(ff - f_target)) lo, hi =max(0, target - half), min(len(pxx), target + half +1) idx = np.arange(lo, hi) idx = idx[np.abs(idx - target) > excl]iflen(idx) ==0:return0.0return pxx[target] / pxx[idx].mean()def epoch_snr_features(epoch, fs): feats = []for ch inrange(epoch.shape[0]): ff, pxx = channel_psd(epoch[ch], fs)for f in STIM_FREQS:for h in HARMONICS: feats.append(snr_at(ff, pxx, h * f))return np.array(feats)snr_matrix = np.stack([epoch_snr_features(epochs[i], fs) for i inrange(len(epochs))])print(f"snr_matrix shape: {snr_matrix.shape}")
snr_matrix shape: (20, 64)
Code
sorted_snr = snr_matrix[order]fig, ax = plt.subplots(figsize=(13, 5))im = ax.imshow(sorted_snr, aspect="auto", origin="upper", cmap="viridis")for i inrange(1, len(group_labels)): ax.axvline(i * n_per_block -0.5, color="white", lw=0.8)for r in class_changes: ax.axhline(r, color="white", lw=0.8)ax.set_xticks([i * n_per_block + n_per_block /2-0.5for i inrange(len(group_labels))])ax.set_xticklabels(group_labels)ax.set_xlabel("Feature group (eight channels sampled at each frequency)")ax.set_yticks(yt)ax.set_yticklabels([f"{c} Hz"for c insorted(set(sorted_labels))])ax.set_ylabel("Trial class (5 trials each)")fig.colorbar(im, ax=ax, label="SNR")fig.tight_layout()fig.savefig("images/05-spectral-features_snr_matrix.png", dpi=200, bbox_inches="tight")plt.show()
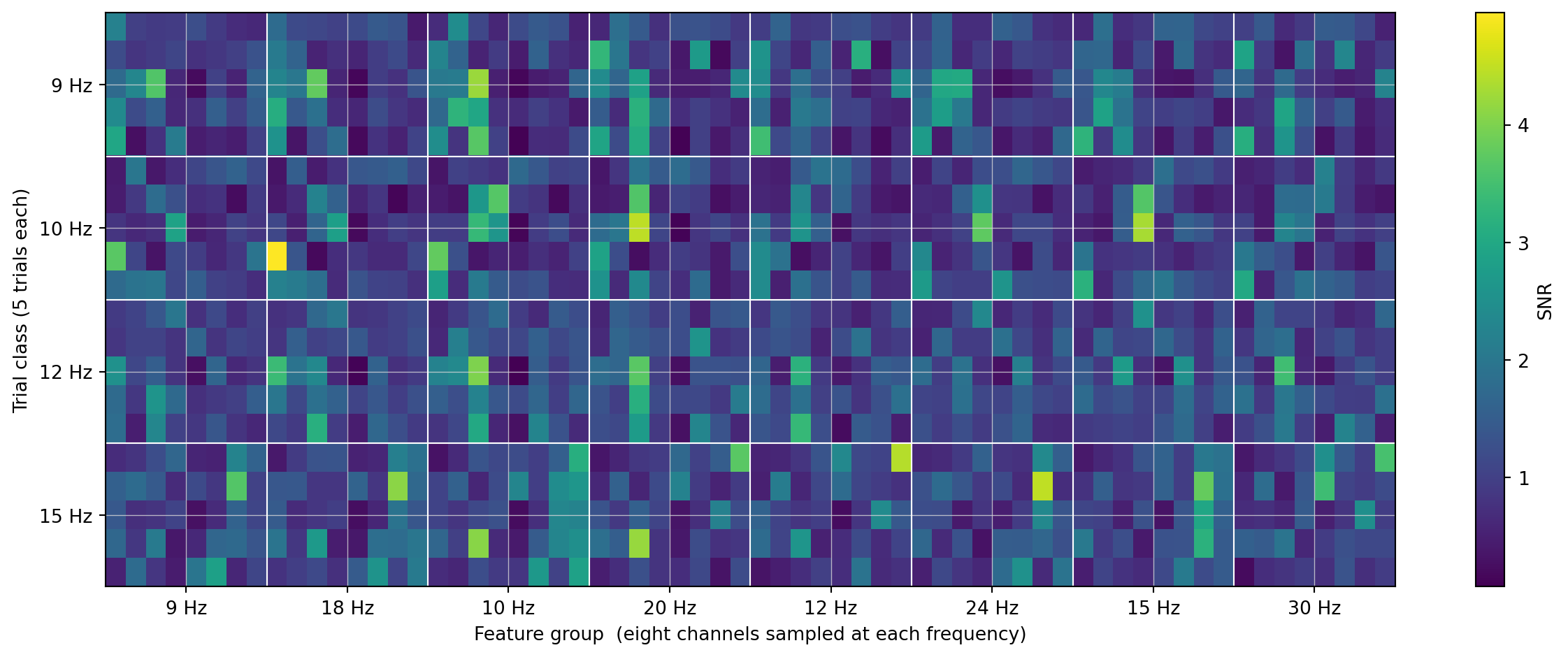
Figure 5.7: SNR feature matrix — same layout, but each cell is power at the target bin divided by mean power in adjacent bins.
The contrast sharpens. The brightest cells in each row are now even more concentrated in the column corresponding to that trial’s stimulation frequency, and the cross-class noise (especially in the 12/15 Hz blocks) drops away. SNR features are what we’ll feed to the classifier in Ch 7. The next chapter (Ch 6) develops a different family of features — template matching with CCA — that doesn’t need to commit to specific harmonics in advance.