The trial structure isn’t documented anywhere in the dataset. Reconstruct it from CH10, decide on epoch boundaries, and produce a tidy (trials × channels × time) array that every later chapter will consume.
4.1 Loading and filtering
Same setup as Ch 3 — running example, filter chain applied to all eight EEG channels. CH10 (the trigger) and CH11 (the LDA output) are integer step functions; filtering would smear them, so we leave them alone.
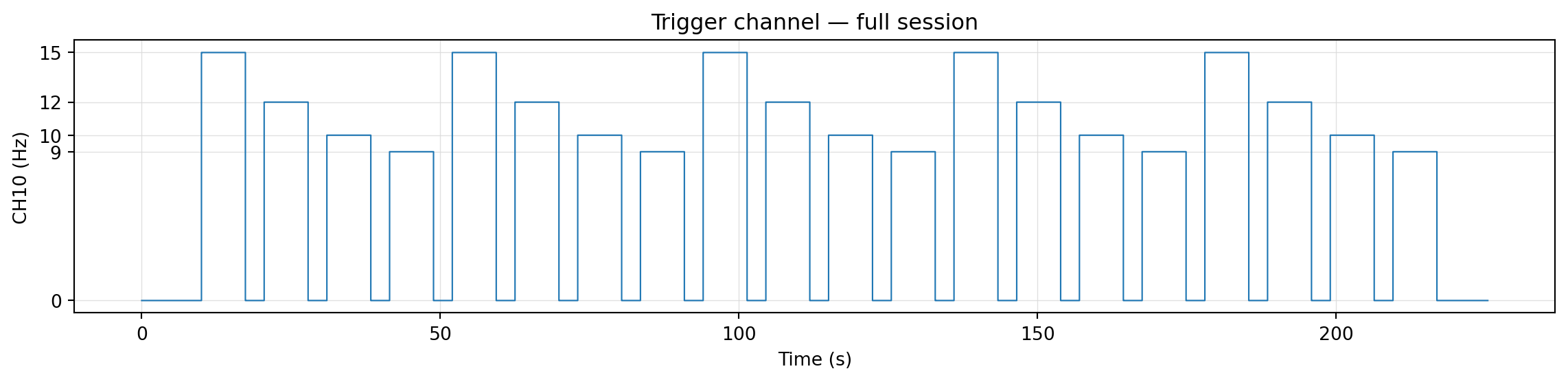
Figure 4.1: CH10 across the full session — the only document of trial structure we have.
A clean step function. CH10 sits at zero between trials and steps to one of {9, 10, 12, 15} while a stimulation block is active. The plateaus look identical in width and the rests between them look identical too — that’s the experimental schedule, hardcoded in g.tec’s stimulator. The class sequence cycles 15 → 12 → 10 → 9 and repeats five times. None of this is documented in data_description.txt; everything we know about trial timing comes from staring at this one channel.
4.3 Detecting trial boundaries
Code
def find_trials(y):"""Return [(start_idx, end_idx, freq_hz), ...] from CH10 transitions.""" ch10 = y[9].astype(int) active = (ch10 !=0).astype(int) diff = np.diff(active) starts = np.where(diff ==1)[0] +1 ends = np.where(diff ==-1)[0] +1return [(int(s), int(e), int(ch10[s])) for s, e inzip(starts, ends)]trials = find_trials(y)durations =sorted({round((e - s) / fs, 3) for s, e, _ in trials})print(f"Trials detected: {len(trials)}")print(f"Distinct durations (s): {durations}")print(f"First five trials (start_s, end_s, duration_s, class):")for s, e, fr in trials[:5]:print(f" ({s / fs:6.2f}, {e / fs:6.2f}, {(e - s) / fs:5.2f}, {fr})")
Edge detection on (CH10 != 0): rising edges mark trial onsets, falling edges mark offsets. Twenty trials, all exactly 7.36 s long. The fact that every trial is the same length is convenient — it lets us build a rectangular tensor without padding decisions.
4.4 Trials per class
Code
classes =sorted({fr for _, _, fr in trials})counts = [sum(1for _, _, fr in trials if fr == c) for c in classes]fig, ax = plt.subplots(figsize=(7, 3.5))bars = ax.bar([str(c) for c in classes], counts, color=["C0", "C1", "C2", "C3"])for bar, c inzip(bars, counts): ax.text(bar.get_x() + bar.get_width() /2, c +0.05, str(c), ha="center", fontsize=10)ax.set_xlabel("Stimulation class (Hz)")ax.set_ylabel("Trials")ax.set_ylim(0, max(counts) +1)ax.set_title("Trials per class — running session")fig.tight_layout()fig.savefig("images/04-epoching_trial_counts.png", dpi=200, bbox_inches="tight")plt.show()
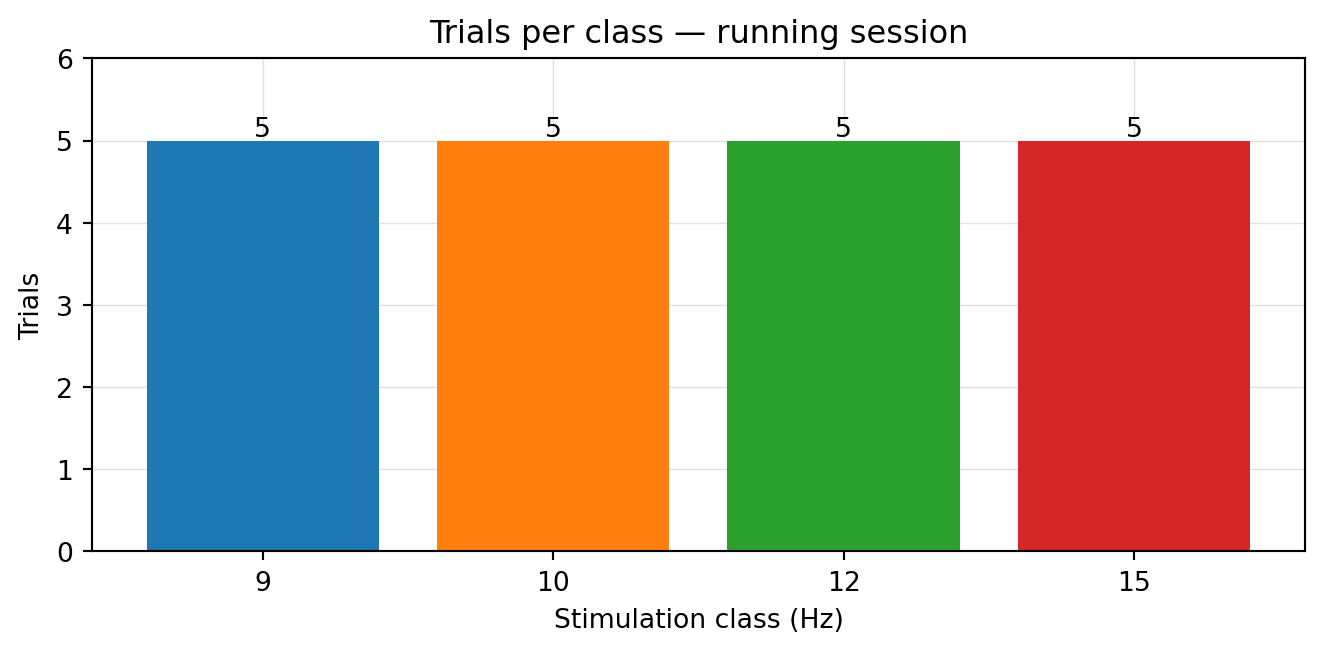
Figure 4.2: Trial count per stimulation class.
Five trials per class, perfectly balanced. Class balance matters for the classifier in Ch 7: an imbalanced training set biases the decision boundary toward the majority class. Five is a small training set per class — for now it’s what we have, and we’ll lean on cross-validation rather than a held-out split when we actually fit a model.
4.5 Building the epoch tensor
Code
def epoch(y_filt, trials, eeg_idx=slice(1, 9)):"""Stack trials into (n_trials, n_channels, n_samples). All trials must share length.""" lengths = {e - s for s, e, _ in trials}iflen(lengths) !=1:raiseValueError(f"Trials have varying lengths: {lengths}") n_samples = lengths.pop() epochs = np.stack([y_filt[eeg_idx, s:s + n_samples] for s, _, _ in trials]) labels = np.array([fr for _, _, fr in trials])return epochs, labelsepochs, labels = epoch(y_filt, trials)print(f"epochs shape: {epochs.shape} (n_trials, n_channels, n_samples)")print(f"labels shape: {labels.shape}, unique: {sorted(set(labels))}")print(f"Per-trial duration: {epochs.shape[2] / fs:.2f} s")
This is the artifact every later chapter consumes. epochs is (20, 8, 1884) — twenty trials × eight EEG channels × 1884 samples (≈7.36 s at 256 Hz). labels is (20,) with values in {9, 10, 12, 15}. Slicing this tensor is how features get computed (Ch 5), how train/test splits get made (Ch 7), and how truncated-window experiments get run (Ch 8).
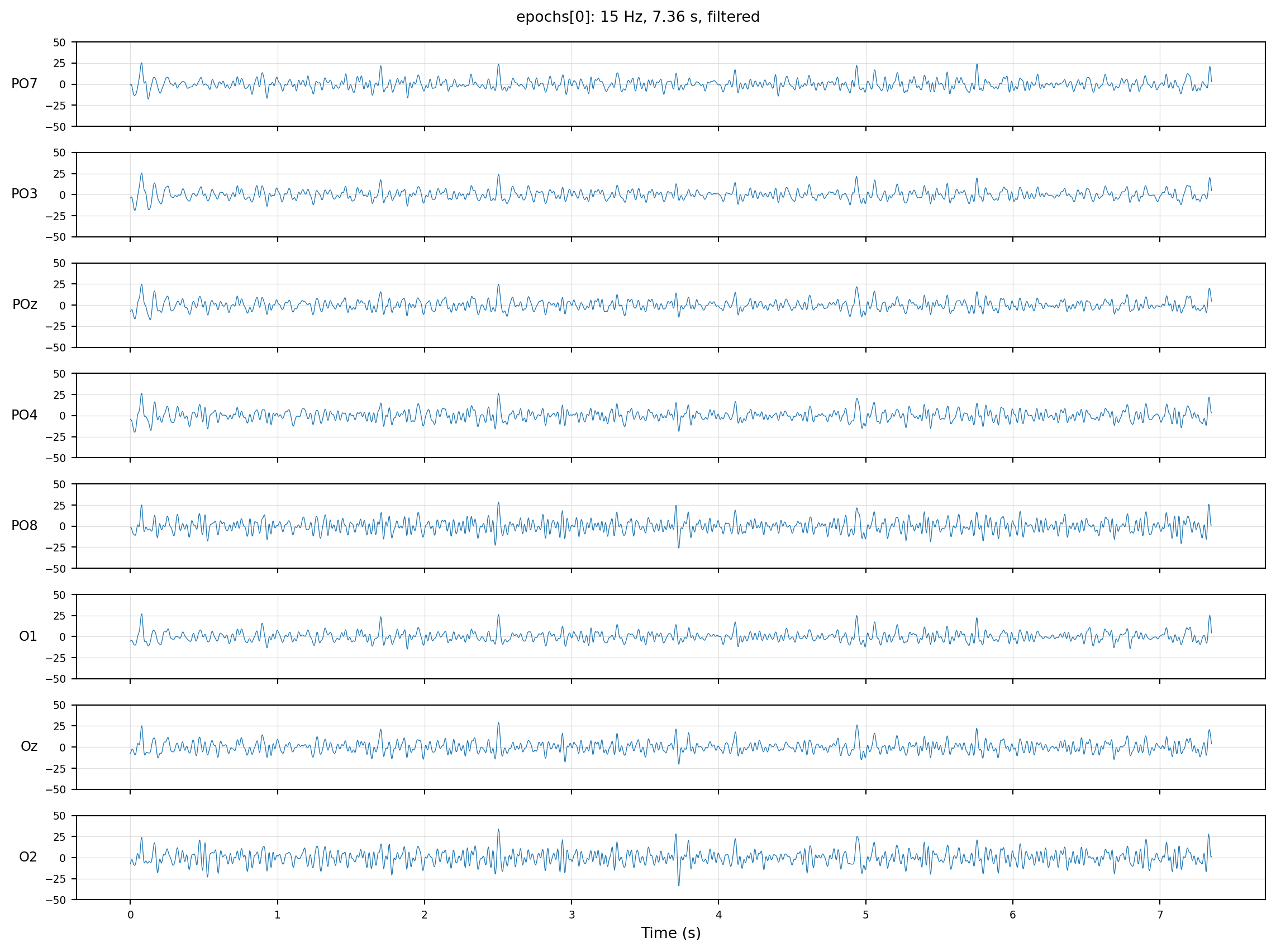
Figure 4.3: One epoch from the tensor — eight channels of the first trial, after filtering.
One trial, eight channels, the same shape that’s now stacked across all twenty. The slow baseline drift that wandered across the time-domain plots in Ch 3 is gone — this is what filtered, epoched data looks like, and from here on every chart will be built from epochs[i] slices.
4.6 Epoch length and the BCI tradeoff
We’ve used the full 7.36 s of each trial as the epoch length, which is generous. Longer epochs give more cycles of the SSVEP and so a more stable spectral estimate; they also mean the BCI has to wait longer before producing each decision. A real-time SSVEP keyboard typically operates on 1–4 s windows — short enough to feel responsive, long enough that the dominant peak is reliable. We come back to this in Ch 8 (time vs accuracy vs ITR), where we re-run the classifier on truncated epochs and trace out the tradeoff curve. For Ch 5 through Ch 7 we stay with the full-trial epoch as a baseline.